Descripció
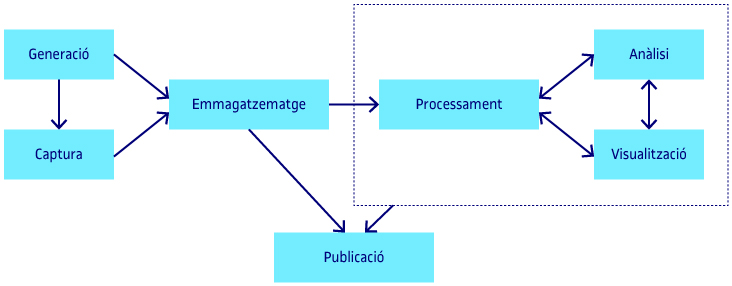
Des del moment de la seva creació o generació, les dades segueixen un cicle de vida fins que acaben essent publicades per a la seva disseminació i també integrades en la implementació dels models creats. Les fases no són completament lineals, i en molts casos poden superposar-se o bé interactuar entre elles. Al llarg d’aquest procés, en cadascuna de les etapes o fases, hi ha un objectiu únic (o més específic) que aporta valor. Encara que no totes les fases són necessàries en funció del tipus de dada, la seva naturalesa o l’objectiu final, les principals etapes del cicle de vida són les següents:
- Generació: les dades es generen com a resultat d’un o més processos, com ara el pagament amb una targeta de crèdit o les interaccions entre els usuaris d’una xarxa social.
- Captura: en alguns casos, les dades generades ja s’emmagatzemen directament, però en d’altres caldrà anar a buscar-les i accedir-hi, ja sigui mitjançant procediments establerts (com una API) o bé desenvolupant procediments d’extracció (amb eines de scraping).
- Emmagatzematge: les dades es poden emmagatzemar en fitxers plans, bases de dades relacionals, però també en d’altres que exploten la seva natura, com ara bases de dades orientades a grafs, o a columnes, etc.
- Processament: normalment, abans de procedir amb l’anàlisi és necessari processar les dades per diferents raons, bàsicament per a seleccionar les que formaran part de l’anàlisi i també calcular noves variables a partir de les originals.
- Anàlisi: l’objectiu d’aquesta etapa és extreure coneixement de les dades, en forma de models que permetin explicar relacions, detectar patrons i tendències, fer prediccions, etc.
- Visualització: l’objectiu d’aquesta fase és doble; per una banda, complementar l’anàlisi mitjançant l’ús de visualitzacions que proporcionin coneixement sobre les dades, i per l’altra, la creació de visualitzacions que mostrin les característiques més rellevants de les dades, i responguin a una pregunta concreta que forma part de l’anàlisi.
- Publicació: les dades, normalment ja processades o bé el resultat dels models analítics construïts es poden publicar de forma que tercers puguin explotar-les.
Exemple d’ús
Un dels problemes actuals en les xarxes socials són les notícies falses i els perfils falsos (bots) que es dediquen a propagar-les. Lluitar contra aquests bots passa per identificar-los i així poder exposar-los i bloquejar-los. El procés per a construir un sistema que identifiqui bots és un bon exemple del cicle de vida de les dades, en aquest cas provinents de Twitter:
- Generació: milers d’usuaris de Twitter generen tuits al voltant d’una etiqueta.
- Captura: usant l’API de Twitter o altres mecanismes, es captura aquest flux de tuits així com els perfils dels usuaris involucrats. Normalment, es tracta de dades en format JSON.
- Emmagatzemament: tant els tuits com els usuaris que participen en una «conversa» al voltant d’una etiqueta formen un graf que pot ser emmagatzemat usant una base de dades orientada a grafs, com ara Neo4j.
- Processament: per a analitzar el comportament dels usuaris no cal tota la informació recollida en la captura dels tuits, així que un primer processament consistirà en seleccionar només algunes característiques que es consideren bàsiques per a identificar bots, com ara el nom, la data de creació, l’existència de descripció i icona, la llista de seguidors i seguits, etc.
- Anàlisi: usant diferents models és possible detectar bots a partir de la seva activitat (o absència), i altres característiques del seu perfil, com ara noms amb números, dates de creació molt recents, manca d’icona personal, etc.
- Visualització: en paral·lel, la xarxa de seguidors i seguits de cada usuari permet detectar fàcilment bots que han estat creats per a donar suport a un usuari concret i detectar subgrafs sospitosos.
- Publicació: en aquest cas, les dades a publicar podrien ser la llista d’usuaris involucrats i la seva classificació com a bot (o la probabilitat de ser-ho).
L’eina Botometer és el resultat d’un procés segurament semblant al descrit en els punts anteriors. A partir del perfil d’un usuari de Twitter, analitza diferents aspectes relacionats amb la seva activitat i determina si es tracta d’un bot o no, i proporciona un informe detallat sobre aquest.
Enllaços relacionats
Botometer: https://botometer.iuni.iu.edu/
Fitxa de Neo4j: https://datascience.recursos.uoc.edu/neo4j/