Descripción
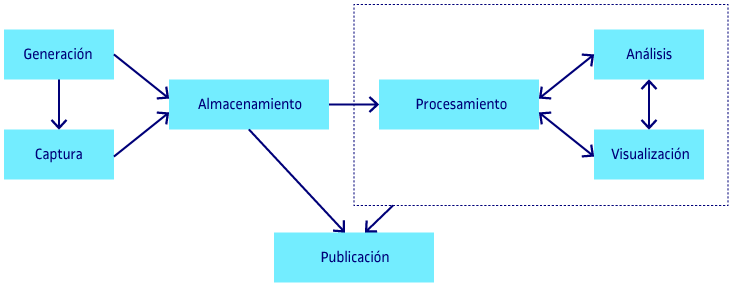
Desde el momento de su creación o generación, los datos siguen un ciclo de vida hasta que se publican para su diseminación y también se integran en la implementación de los modelos creados. Las fases no son completamente lineales, y en muchos casos pueden superponerse o interactuar entre sí. A lo largo de este proceso, en cada etapa o fase, hay un único objetivo (o más específico) que aporta valor. Aunque no todas las fases son necesarias en función del tipo de dato, su naturaleza o el objetivo final, las principales etapas del ciclo de vida son las siguientes:
- Generación: los datos se generan como resultado de uno o más procesos, como el pago con una tarjeta de crédito o las interacciones entre los usuarios de una red social.
- Captura: en algunos casos, los datos generados ya se almacenan directamente, pero es necesario buscarlos y acceder a otros, ya sea mediante procedimientos establecidos (como una API) o mediante el desarrollo de procedimientos de extracción (con herramientas de scraping).
- Almacenamiento: los datos se pueden almacenar en archivos planos, bases de datos relacionales, pero también en otros que explotan su naturaleza, como bases de datos orientadas a grafos, o columnas, etc.
- Procesamiento: normalmente antes de proceder con el análisis es necesario procesar los datos por diferentes razones, básicamente para seleccionar los que formarán parte del análisis y también calcular nuevas variables a partir de los originales.
- Análisis: el objetivo de esta etapa es extraer conocimiento de los datos, en forma de modelos que permitan explicar relaciones, detectar patrones y tendencias, hacer predicciones, etc.
- Visualización: el objetivo de esta etapa es doble; por un lado, complementar el análisis mediante visualizaciones que proporcionen conocimiento sobre los datos, y por otro lado, la creación de visualizaciones que muestren las características más relevantes de los datos, y respondan a una pregunta concreta parte del análisis.
- Publicación: los datos, normalmente ya procesados o el resultado de los modelos analíticos construidos pueden publicarse para que terceros puedan explotarlos.
Ejemplo de uso
Uno de los problemas actuales en las redes sociales son las noticias falsas y los perfiles falsos (bots) que se dedican a propagarlas. Luchar contra estos bots es una manera de identificarlos y así poderlos exponer y bloquear. El proceso para construir un sistema que identifica a los bots es un buen ejemplo del ciclo de vida de los datos, en este caso procedentes de Twitter:
- Generación: miles de usuarios de Twitter generan tuits alrededor de una etiqueta.
- Captura: con la API de Twitter u otros mecanismos, se captura ese flujo de tuits, así como los perfiles de los usuarios involucrados. Normalmente, son datos en formato JSON.
- Almacenamiento: tanto los tuits como los usuarios que participan en una «conversación» alrededor de una etiqueta forman un grafo que se puede almacenar mediante una base de datos orientada a grafos, como Neo4j.
- Procesamiento: para analizar el comportamiento de los usuarios no es necesaria toda la información recopilada en la captura de los tuits, por lo que un primer procesamiento consistirá en seleccionar solo algunas características que se consideran básicas para identificar a los bots, como nombre, fecha de creación, existencia de descripción e icono, la lista de seguidores y seguidos, etc.
- Análisis: con el uso de diferentes modelos es posible detectar a los bots a partir de su actividad (o ausencia), y otras características de su perfil, como nombres con números, fechas de creación muy recientes, falta de icono personal, etc.
- Pantalla: en paralelo, la red de seguidores y seguidos por cada usuario permite detectar fácilmente a los bots que se han creado para apoyar a un usuario específico y detectar a subgrafos sospechosos.
- Publicación: en este caso, los datos que se publicarán podrían ser la lista de usuarios implicados y su clasificación como bot (o la probabilidad de serlo).
La herramienta Botometer es el resultado de un proceso que seguramente es similar al descrito en los puntos anteriores. A partir del perfil de un usuario de Twitter, analiza diferentes aspectos relacionados con su actividad y determina si es un bot o no, y proporciona un informe detallado al respecto.
Enlaces relacionados
Botometer: https://botometer.iuni.iu.edu/
Ficha de Neo4j: https://datascience.recursos.uoc.edu/neo4j/