Descripción
Se trata de una aplicación multiplataforma (Mac, Windows y Linux) que permite la extracción de tablas contenidas en ficheros formato PDF, y la posibilidad de exportar dichas tablas a formato CSV o XLS.
Su funcionamiento es muy sencillo e intuitivo, simplemente es necesario cargar el PDF deseado y seleccionar la tabla o tablas por extraer, indicando el formato de salida deseado. Es importante destacar que la extracción solo puede realizarse en ficheros de texto PDF, no soporta documentos escaneados provenientes de formatos gráficos tipo bitmap (PNG, TIFF).
Enlace al recurso
Ejemplos de uso
En este ejemplo extraeremos una tabla que se encuentra en un fichero PDF y la exportaremos a formato csv. El fichero PDF que utilizaremos como fuente de datos es el siguiente: http://www.uoc.edu/portal/_resources/CA/documents/persones/plantilla_UOC_-_Estructura_agost_2018.pdf
Los pasos que seguir utilizando Tabula son:
1) Importar el fichero PDF a la herramienta.
2) Seleccionar de forma visual e interactuando con Tabula la tabla sobre la que queremos extraer los datos; en este caso, se trata de la tabla «Personal d’estructura» o mediante el sistema de autodetección de tablas.
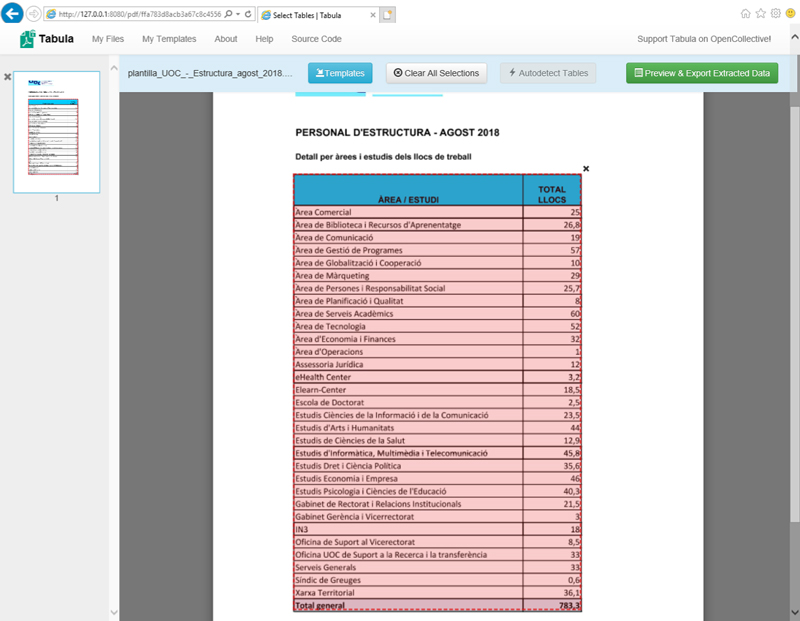
3) Avanzamos al paso de previsualización y exportación de datos, donde podremos validar que la información y la estructura es correcta:
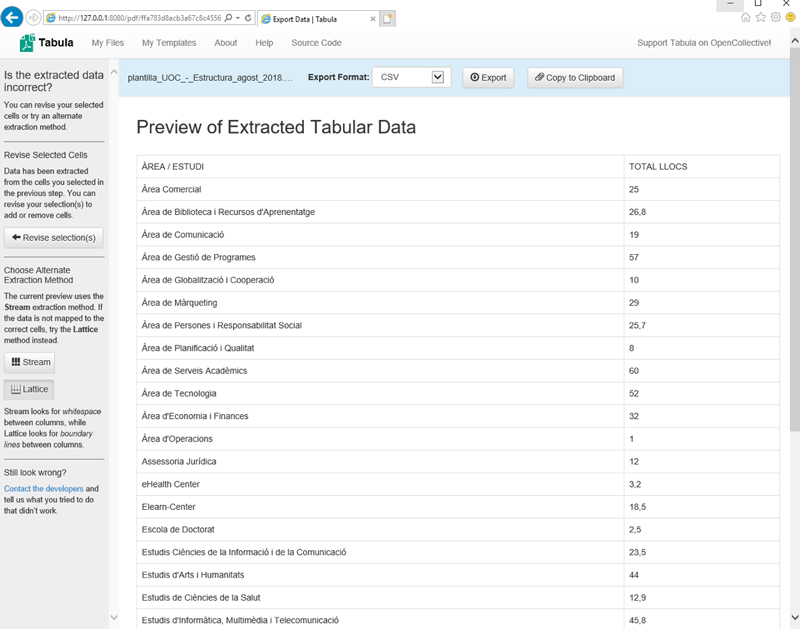
4) Por último, seleccionaremos el formato csv para exportar la información.