Descripción
Plataforma totalmente interactiva que permite el preprocesado de datos (ETL: Extraction, Transformation, Loading), la creación de modelos, el análisis de datos y visualización, sin que sea necesaria la programación.
El panel de trabajo está diseñado de forma que podamos utilizarlo interactivamente (drag & drop) con nodos y relaciones. Cada uno de los nodos representa un algoritmo mientras que las flechas son flujos de datos. Además de los propios algoritmos incluidos (más de dos mil), en la solución es posible incluir scripts de R, Python o conectores de Apache Spark.
Los datos se pueden obtener de diferentes fuentes, desde simples ficheros de texto (CSV, PDF, XLS, JSON, XML, etc.) hasta tipos de datos no estructurados como imágenes, o documentos, e incluso series de datos temporales. Por otra parte, podemos conectar con bases de datos y data warehouses de Oracle Microsoft SQL, Apache Hive, entre otros. El acceso a otras fuentes de datos como Azure, Twitter, Google Sheets, AWS S3, fichero ORC también se encuentra soportado.
KNIME también permite la visualización de datos en diagramas de barras, dispersión, redes… Otra característica de especial interés es la posibilidad de exportar a PDF, PowerPoint o almacenar los resultados en diferentes formatos de ficheros o bases de datos.
Enlace al recurso
Ejemplos de uso
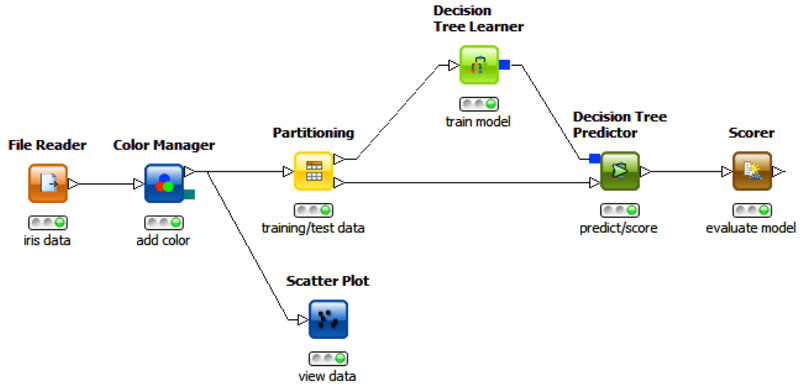
KNIME ofrece múltiples posibilidades desde visualización o tratamiento de datos a modelización. En este caso, nos centraremos en la creación de un modelo mediante árboles de decisión. En esta herramienta trabajamos con nodos que uno a uno se transfieren la información mediante conexiones. Partimos de que la información se encuentra almacenada en un fichero plano de texto en formato csv. Seguidamente, representaremos la información en un diagrama de dispersión (scatter plot). A la hora de comenzar el modelo, tenemos que dividir nuestro dataset entre el conjunto de entrenamiento y de test, para lo que aplicaremos un nodo de particionamiento. En el siguiente paso, utilizaremos un nodo que nos permita realizar el entrenamiento del modelo, Decision Tree Learner, tomando como entrada el conjunto de entrenamiento que hemos definido anteriormente. Una vez que se encuentra entrenado el modelo, debemos realizar el testing del modelo utilizando tanto el conjunto de testing como el modelo entrenado, para ello necesitaremos utilizar un nodo Decision Tree Predictor que nos informará del resultado de este test, pudiendo aplicar si lo deseamos un nodo Scorer para obtener la matriz de confusión y sus métricas asociadas.