
Descripción
Esta colección de recursos, seleccionada por Eugene Yan, contiene decenas de ejemplos reales de implementaciones de soluciones basadas en aprendizaje automático. Los ejemplos, descritos en forma de artículos, cubren la mayoría de las fases del ciclo de vida de los datos, así como ámbitos de aplicación. Entre otros, se pueden destacar los ejemplos de captura y manipulación de datos masivos de empresas como Netflix, Airbnb o Uber, clasificación y predicción, sistemas de recomendación y búsqueda de información, sistemas de procesamiento de lenguaje natural o de visión por computador, etc.
La compilación termina con dos apartados muy interesantes. El primero es una compilación de consejos sobre los equipos que deben construir e implementar modelos y otras herramientas derivadas. El segundo es una lista de proyectos que han fracasado, la mayoría relacionados con la puesta en marcha de sistemas de inteligencia artificial, como por ejemplo un sistema que predice el crimen basándose en la cara que pone el potencial malhechor.
Enlace al recurso
https://github.com/eugeneyan/applied-ml
Ejemplo de uso
En la lista hay unos cuántos artículos relacionados con Spotify, principalmente sobre cómo funciona el sistema que permite que nos recomiende música cada semana, encontrando un punto de equilibrio entre lo que Spotify sabe que conocemos y que nos gusta (porque lo escuchamos muy a menudo, lo tenemos guardado en las listas de reproducción o descargado para escucharlo fuera de línea) y lo que todavía desconocemos (según lo que «piensa» Spotify). Para ello usan una combinación de algoritmos y de técnicas de minería de datos, entre otras, la que se conoce como reinforcement learning. Los resultados muestran que es posible recomendar música nueva a las personas usuarias, distinta de la que escuchan habitualmente y que está bien valorada. El siguiente gráfico muestra la arquitectura del sistema de recomendación:
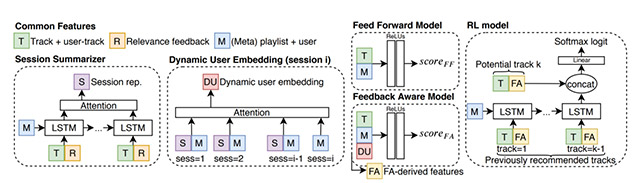
En las asignaturas Infraestructuras tecnológicas por Big Data y Aprendizaje automático del grado de Ciencia de Datos Aplicada de la UOC estudiaréis algunos de los conceptos mencionados.
Enlaces relacionados
Recomendando música nueva a las personas usuarias de Spotify: https://research.atspotify.com/shifting-consumption-towards-diverse-content-via-reinforcement-learning/