Descripción
Cuando se construye un clasificador es importante estimar el error cometido, de forma que sea posible compararlo con otros clasificadores y/o realizar ajustes en los parámetros de dicho clasificador. Es especialmente importante saber cómo se comportará el clasificador con datos nuevos que nunca han sido vistos anteriormente, es decir, que no fueron usados para entrenarlo. En otras palabras, es necesario poder estimar cómo de preciso será el clasificador o cómo de bien generalizará.
Es muy fácil caer en el error de construir un clasificador que funciona muy bien para los datos disponibles (hasta el punto de llegar en algunos casos al cien por cien de precisión si los datos lo permiten), pero que no funciona tan bien para datos nunca vistos anteriormente. Para evitar este problema lo que se suele hacer es partir el conjunto de datos en dos subconjuntos, uno de entrenamiento y otro de test, de forma que el clasificador se construye con el primero y su precisión se evalúa con el segundo.
Existen muchas maneras de partir el conjunto de datos inicial en dos (entrenamiento y test), entre ellas la conocida como N-Fold Cross-Validation (NFCV, a veces también kFCV), que intenta aprovechar al máximo las particiones generadas. Básicamente, el conjunto inicial se divide en N partes similares, tanto por tamaño como idealmente por la distribución de la variable objetivo. Entonces, el conjunto de test consiste en una de estas N partes y el conjunto de entrenamiento en las N – 1 restantes. Para cada partición posible (N en total), se construye un clasificador y se evalúa con el conjunto de test, por lo que la precisión «media» del clasificador se obtiene combinando los N resultados obtenidos, los cuales idealmente no deberían ser muy diferentes. Si es así, esto quiere decir que las particiones están generando conjuntos de entrenamiento y/o de test muy diferentes entre sí, lo cual no es recomendable.
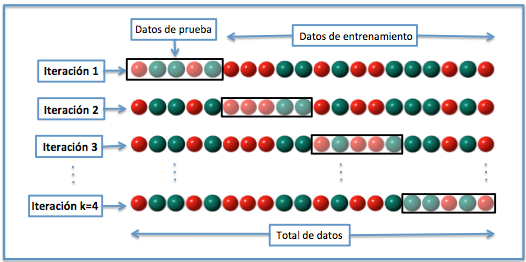
Ejemplo de N-Fold Cross Validation. Fuente: Wikipedia.
Normalmente N (o k) se escoge en un rango de valores limitado, en el que 2, 3, 5 o 10 son valores típicos. Cuanto mayor sea el número de particiones, más precisa será la estimación del error del clasificador, siempre y cuando las particiones no sean muy diferentes entre sí. Por el contrario, la necesidad de construir y evaluar un clasificador para cada partición de las N posibles tiene un coste mayor para valores de N elevados.
Un caso extremo es cuando N se escoge igual al número de elementos del conjunto de datos, por lo que se construyen N clasificadores, entrenados con todos los datos disponibles excepto uno, que se usa para evaluar su precisión. Este caso se conoce como LOO, acrónimo de Leave One Out, y es útil para conjuntos de datos «pequeños», dado que hay que construir y evaluar tantos clasificadores como datos tiene el conjunto original.
Finalmente, como la partición en N conjuntos es aleatoria, este proceso se puede repetir un cierto número de veces y calcular el promedio de la precisión obtenida en cada caso.
Enlace al recurso
https://en.wikipedia.org/wiki/Cross-validation_(statistics)
Ejemplo de uso
Existen muchos paquetes en R, Python, etc. que facilitan la creación de las particiones, como el package caret de R, por ejemplo, o scikit-learn (sklearn) en Python. En el caso de R, el siguiente ejemplo muestra cómo entrenar y validar un clasificador para el conocido conjunto iris:
# cargar el package library(caret) # cargar el dataset iris data(iris) # establecer cómo se realiza el entrenamiento # cross-validation con 10 folds train_control <- trainControl(method="cv", number=10) # parámetros del modelo grid <- expand.grid(<aquí irían los parámetros del modelo>) # entrenar el modelo model <- train(Species~., data=iris, trControl=train_control, method="<modelo>", tuneGrid=grid) # mostrar resultados print(model)
Enlaces relacionados
Recurso: https://datascience.recursos.uoc.edu/es/el-package-caret-de-r/
El package caret de R: https://cran.r-project.org/web/packages/caret/vignettes/caret.html