Descripción
Weka (Waikato Environment for Knowledge Analysis) es una plataforma software de machine learning y minería de datos que contiene una colección de herramientas de visualización y algoritmos para análisis de datos y modelado predictivo. En Weka encontraremos funcionalidades orientadas a la preparación de los datos, así como algoritmos de clasificación, regresión, clustering, reglas de asociación y ciertas características para la visualización de datos.
Para aprender con detalle el uso de esta herramienta y manteneros actualizados de todas aquellas capacidades que se van incorporando a Weka, la Universidad de Waikato pone a nuestra disposición una gran cantidad de recursos formativos.
Enlace al recurso
https://www.cs.waikato.ac.nz/~ml/weka
Ejemplos de uso
En el siguiente ejemplo veremos cómo realizar un modelo de clasificación utilizando el algoritmo random forest en Weka. Partiremos de nuestro fichero de datos en formato csv, que utilizaremos como fuente de información; en este caso, usaremos el famoso dataset Iris Flowers (iris.csv), que contiene 150 observaciones (filas) y 5 atributos (columnas), en el que se detalla para cada tipo de flor (iris setosa, iris versicolour e iris virginica) la longitud y la anchura del sépalo y pétalo.
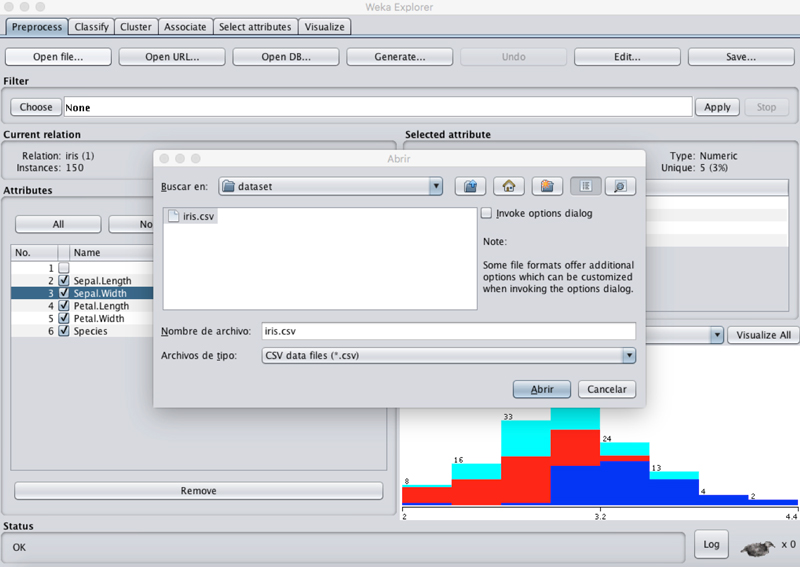
Posteriormente, en el apartado de «clasificación» comenzaremos a crear el modelo seleccionado entre los diferentes clasificadores soportados por la herramienta. En nuestro caso, usaremos random forest, indicando que utilice un 70 % del conjunto de datos para entrenamiento del modelo. Seguidamente, ya podremos comenzar el proceso de generación del modelo y analizar los resultados, entre los que podremos encontrar la matriz de confusión, así como la precisión del modelo generado.
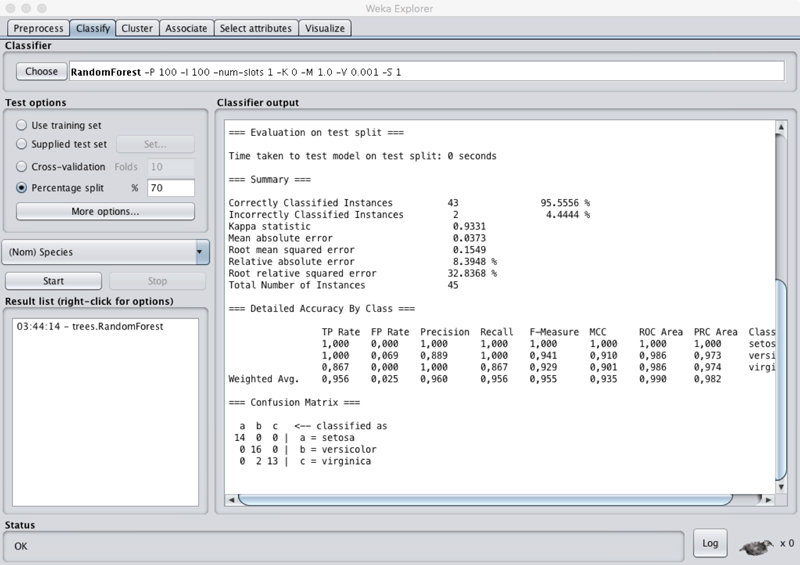
Enlaces relacionados
https://en.wikipedia.org/wiki/Weka_(machine_learning)
https://www.cs.waikato.ac.nz/ml/weka/courses.html
https://machinelearningmastery.com/how-to-run-your-first-classifier-in-weka/