Descripció
Quan es construeix un classificador és important estimar l’error comès, de manera que sigui possible comparar-lo amb altres classificadors i/o fer ajustos en els paràmetres d’aquest classificador. És especialment important saber com es comportarà el classificador amb dades noves que mai no han estat vistes anteriorment, és a dir, que no es van usar per a entrenar-lo. En altres paraules, és necessari poder estimar com de precís serà el classificador o com de bé generalitzarà.
És molt fàcil caure en l’error de construir un classificador que funciona molt bé per a les dades disponibles (fins al punt d’arribar en alguns casos al cent per cent de precisió si les dades ho permeten), però que no funciona tan bé per a dades mai vistes anteriorment. Per evitar aquest problema, el que se sol fer és partir el conjunt de dades en dos subconjunts, un d’entrenament i un altre de test, de manera que el classificador es construeix amb el primer i la seva precisió s’avalua amb el segon.
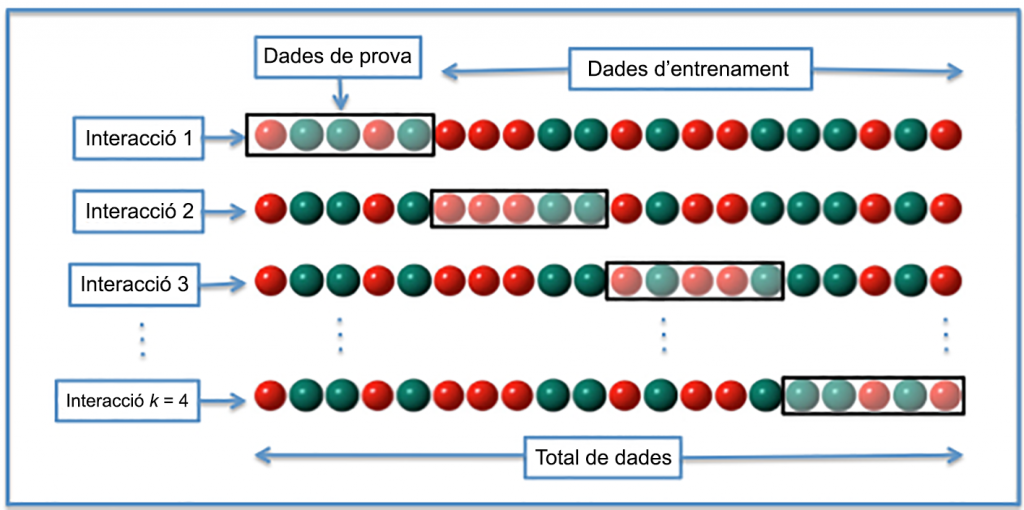
Hi ha moltes maneres de partir el conjunt de dades inicial en dos (entrenament i test), entre elles la coneguda com a N-Fold Cross-Validation (NFCV, de vegades també kFCV), que intenta aprofitar al màxim les particions generades. Bàsicament, el conjunt inicial es divideix en N parts semblants, tant per grandària com idealment per la distribució de la variable objectiu. Llavors, el conjunt de test consisteix en una d’aquestes N parts i el conjunt d’entrenament en les N – 1 restants. Per a cada partició possible (N en total), es construeix un classificador i s’avalua amb el conjunt de test, per la qual cosa la precisió «mitjana» del classificador s’obté combinant els N resultats obtinguts, que idealment no haurien de ser gaire diferents. Si és així, això vol dir que les particions estan generant conjunts d’entrenament i/o de test molt diferents entre si, la qual cosa no és recomanable.
Font: Viquipèdia
Normalment N (o k) s’escull en un rang de valors limitat, en el qual 2, 3, 5 o 10 són valors típics. Com més gran sigui el nombre de particions, més precisa serà l’estimació de l’error del classificador, sempre que les particions no siguin gaire diferents entre si. Per contra, la necessitat de construir i avaluar un classificador per a cada partició de les N possibles té un cost més gran per a valors de N elevats.
Un cas extrem és quan N s’escull igual al nombre d’elements del conjunt de dades, per la qual cosa es construeixen N classificadors, entrenats amb totes les dades disponibles excepte una, que s’usa per a avaluar-ne la precisió. Aquest cas es coneix com LOO, acrònim de Leave One Out, i és útil per a conjunts de dades «petites», atès que cal construir i avaluar tants classificadors com dades té el conjunt original.
Finalment, com que la partició en N conjunts és aleatòria, aquest procés es pot repetir un cert nombre de vegades i calcular la mitjana de la precisió obtinguda en cada cas.
Enllaç al recurs
https://en.wikipedia.org/wiki/cross-validation_(statistics)
Exemple d’ús
Hi ha molts paquets en R, Python, etc. que faciliten la creació de les particions, com el package caret de R, per exemple, o scikit-learn (sklearn) a Python. En el cas de R, l’exemple següent mostra com es pot entrenar i validar un classificador per al conegut conjunt iris:
# carregar el package library(caret) # carregar el dataset iris data(iris) # establir com es fa l'entrenament # cross-validation amb 10 folds train_control <- trainControl(method="cv", number=10) # paràmetres del model grid <- expand.grid(<aquí anirien els paràmetres del model>) # entrenar el model model <- train(Species~., data=iris, trControl=train_control, method="<model>", tuneGrid=grid) # mostrar resultats print(model)
Enllaços relacionats
Recurs: https://datascience.recursos.uoc.edu/el-package-caret-de-r/
El package caret de R: https://cran.r-project.org/web/packages/caret/vignettes/caret.html